Small Data & Active Learning in de Zorg

Small Data & Active Learning in de Zorg
Data, AI en Machine Learning zijn onderwerpen die veel kansen kunnen bieden in het zorgdomein. We zijn nu in staat veel data te verzamelen en er wordt veel onderzoek gedaan naar mogelijkheden om deze data in te zetten om het leven van een patiënt te verbeteren. Toch zijn er maar weinig voorbeelden van succesvolle Big Data of kunstmatige intelligentie (AI) projecten die in de praktijk waarde opleveren voor de zorg (Hansen, Miron-Shatz, Lau, & Paton, 2014; Sacristán & Dilla, 2015). Veel onderzoek blijft hangen op theoretische toepassingen, en werkt alleen in gecontroleerde omgevingen. Zodra de onberekenbaarheid van de werkelijkheid erbij komt kijken, zijn de toepassingen niet meer effectief.
Tot nu toe gebrek
aan succes
Een van de bekendste voorbeelden van dit probleem is ‘IBM Watson for oncology’. IBM beloofde in 2013 dat Watson in staat zou zijn om met behandelplannen te komen voor kankerpatiënten, gebaseerd op duizenden publicaties en behandeldossiers. Helaas is dit product nooit een succes geworden en is de stekker eruit getrokken.
Dit gebrek aan succes heeft te maken met de volgende belangrijke factoren (Strickland, 2019):
- Wanneer spreek je van een succesvol behandelplan?
Presteert het systeem goed als het dezelfde behandelplannen kan bedenken als een arts, of juist als het systeem andere en hopelijk betere plannen kan bedenken? Dit was onduidelijk in het geval van Watson. Bij een proef in Thailand, waarbij Watson in 83% van de gevallen een gelijksoortig behandelplan bedacht als de arts, werd door artsen gesuggereerd dat Watson geen toegevoegde waarde gaf (Suwanvecho et al., 2017). Bij een andere proef werd in slechts 49% van de gevallen een vergelijkbaar behandelplan opgesteld door Watson en door de arts. Ook deze proef werd als onsuccesvol beschouwd, omdat bepaalde medicatie afweek of standaardmedicatie ontbrak bij de behandelplannen van Watson (Lee et al., 2018). - De echte wereld is geen gecontroleerd experiment.
Data komen uit allerlei bronnen en zijn vaak lastig te bereiken door uitwisselingsproblemen, wetgeving, privacy en uiteenlopende standaarden (Hansen et al., 2014). Daarnaast zijn niet alle data volledig beschikbaar. Dit probleem wordt aangeduid als ‘sparse data’. (Wärnling, Bissmark, & Skolan, 2017). Sparse data zijn schaarse gegevens: de verzameling bevat relatief een hoog percentage “lege” of niet beschikbare waarden. Tabel 1 geeft een voorbeeld van sparse data, waar bij bloedtesten niet op alle beschikbare waarden wordt getest.
| Glucose | Alcohol | Hemoglobine | Lactaat | Magnesium | |
| Patiënt A | 4,0 | 0,5 | – | 1,5 | – |
| Patiënt B | 6,0 | – | – | – | – |
| Patiënt C | – | – | – | – | 1,0 |
| Patiënt D | – | – | 0,5 | – | – |
| Patiënt E | 9,0 | 0,0 | – | 0,5 | – |
Tabel 1: Voorbeeld sparse data waar bij bloedtesten niet alle waarden bekend zijn
- AI is traag met adopteren van nieuwe behandelplannen
De AI kiest geen nieuwe behandelplannen, omdat deze gebaseerd zijn op alle beschikbare data. Maar de nieuwe behandelplannen vormen maar een klein deel van die data. Dus wanneer een nieuwe vorm van behandeling bijzonder succesvol blijkt te zijn, zal een AI nooit direct overschakelen naar dit nieuwe plan zolang er weinig data over beschikbaar is. Dit is een belangrijke fout in de werkwijze waar een oplossing voor gevonden moet worden (Strickland, 2019).
De patiënt staat niet centraal
Op dit moment zijn er nog geen bruikbare AI-oplossingen voor de zorg. Zelfs een groot bedrijf als IBM, met alle middelen die dat bedrijf heeft, is het niet gelukt. We kijken verkeerd naar het gebruik van data en AI in de zorg, want in de praktijk is het lastig om de juiste bronnen aan elkaar te koppelen en daar zinnige informatie voor de behandeling van een patiënt uit te halen. Tot nu toe proberen we behandelingen in de zorg met Big Data te veralgemenen.
Zorg is vanuit het oogpunt van een patiënt niet algemeen te maken, want elke patiënt is uniek. Dus moeten we inzoomen op de patiënt met al zijn of haar unieke problemen en context, en uitgaan van een patiëntgecentreerde oplossing (Sacristán & Dilla, 2015). Eigenlijk is er daardoor geen sprake van Big Data, maar van Small Data, omdat er voor iedere unieke situatie van een patiënt weinig tot geen vergelijkbare voorbeelden zijn. De vraag die we ons moeten is stellen is daarom: hoe gebruiken we grootschalige populatiegebaseerde analyses voor individuele patiënten (Sacristán & Dilla (2015)).
Het antwoord ligt in het gebruik van Small Data en Active Learning. Hiermee kunnen we de patiënt centraal stellen in AI-oplossingen in de zorg.
Small Data & Active Learning
Small Data
Er is sprake van Small Data als de dataset niet groot is en niet doorlopend vergroot of verandert. Small Data worden gemaakt om specifieke onderzoeksvragen te beantwoorden (Kitchin & Lauriault, 2015). Daarmee zijn Small Data precies het tegenovergestelde van Big Data. Ondanks dat Big Data tegenwoordig de focus is, zullen Small Data nooit verdwijnen, omdat ze effectief zijn bij het beantwoorden van specifieke vragen. Normaal gesproken worden Small Datasets vooral onderzocht met klassieke statistiek methoden (Kitchin & Lauriault, 2015).
Active Learning werkt met een kleine set van gelabelde data en een grotere set van ongelabelde data.
Wat is Active Learning
Bij Machine Learning wordt gebruikt gemaakt van gelabelde data. Bijvoorbeeld een afbeelding krijgt een label ‘appel’. Zo leert de machine dat de afbeelding een appel bevat. Active Learning is een methode om betrouwbare Machine Learning toe te passen, zonder dat de volledige set van gegevens labels heeft (Lewis, Gale, Croft, & Van Rijsbergen, 1994). Het labelen van alle gegevens kan veel tijd kosten en daardoor duur zijn. Het toevoegen van labels is vooral tijdrovend bij spraakherkenning, het classificeren van teksten, video en afbeeldingen.
Active Learning werkt met een kleine set van gelabelde data en een grotere set van ongelabelde data. Een algoritme, een zogenaamde classifier, wordt gebruikt om de data te classificeren. Deze classifier kent labels toe aan de ongelabelde gegevens. De labels waarvan de classifier zeker is, worden vervolgens toegevoegd aan de trainingsset om zo in een volgende ronde meer ongelabelde data te classificeren en te labelen (Lewis et al., 1994). Active Learning zorgt voor meer betrouwbare informatie, terwijl er zo min mogelijk labels gecreëerd hoeven te worden om de classifier te trainen (Settles, 2009). Het is zelfs zo dat door een algoritme zelf te laten kiezen op welke data het traint, resultaten beter worden vergeleken met trainen op een volledig gelabelde dataset (Settles, 2009). Dit gaat rechtstreeks in tegen het uitgangspunt dat meer data altijd betere modellen oplevert.
Aanbevelingen met zo min mogelijk trainingsdata
Tegenwoordig wordt Active Learning ook toegepast bij systemen die aanbevelingen doen. Waarbij een gebruiker een aanbeveling krijgt die gebaseerd is op zo min mogelijk trainingsdata. Elke gebruiker is uniek, waardoor voor elke gebruiker dus ook een gepersonaliseerd en zo effectief mogelijk aanbod nodig is (Rubens et al., 2011). Active Learning helpt om met zo min mogelijk trainingsdata de gebruiker zo goed mogelijk te begrijpen. Zo kan de juiste aanbeveling gegeven worden. Naarmate een dergelijk systeem langer in gebruik is, zal het door directe gebruikersfeedback steeds accurater worden. Een extra uitdaging hierbij zijn nieuwe producten. Wanneer je deze toegevoegd aan het systeem, moeten ze snel in de aanbeveling worden meegenomen (Rubens et al., 2011).
Synthesis
Een andere manier om, net als met Active Learning, meer uit Small Datasets te halen, is met synthesis. Synthesis is een techniek waarbij meerdere data-elementen worden gemaakt uit één data-element. Afbeeldingen lenen zich hier goed voor, bijvoorbeeld voor het trainen van gezichtsherkenning. Hoe meer data beschikbaar zijn om op te trainen, hoe beter de getrainde classifier. Als data niet voldoende beschikbaar zijn, kan een bestaand data-element, in dit geval een foto, worden opgedeeld in meerdere delen. De foto wordt simpelweg gespiegeld. Ook worden onderdelen van de foto gebruikt, zoals bijvoorbeeld alleen de neus of de oren. Op deze manier wordt uit één foto 32 data-elementen gedistilleerd. Door deze techniek toe te passen lukt het om met 10.000 afbeeldingen een classifier te bouwen die even goed werkt als een model dat getraind is met 500.000 afbeeldingen (Hu, Peng, Yang, Hospedales, & Verbeek, 2018).
Synthesis is een techniek waarbij meerdere data-elementen worden gemaakt uit één data-element
Toepassingen in de zorg
Wanneer we naar praktische toepassingen van Small Data en Active Learning zoeken in de zorg, zijn er twee soorten te onderscheiden:
- Onderzoeken en toepassingen waarbij het lastig is om voldoende data een label te geven.
- Het centraal stellen van de patiënt.

Onvoldoende data met label
Een van de meer sprekende voorbeelden van Active Learning in de zorg waarbij onvoldoende data met label beschikbaar is, is de toepassing voor het analyseren van afbeeldingen. Bij deze toepassing wordt beoordeeld of een moedervlek wel of geen melanoom is (Gal, Islam, & Ghahramani, 2017). De gebruikte dataset bevat 727 negatieve voorbeelden (moedervlek is geen melanoom) en 173 positieve voorbeelden. Deze dataset is aan de kleine kant voor het toepassen van Machine Learning. Daarnaast is de dataset ongelijk verdeeld, omdat er veel meer voorbeelden negatief dan positief zijn. Dit maakt de dataset minder geschikt. Door het toepassen van Active Learning kon met alleen maar 100 datapunten toch een betrouwbare classifier gebouwd worden, zelfs dus nog minder datapunten dan de al slechts 900 gelabelde beschikbare punten. Dit betekent dat het niet nodig is om veel tijd te besteden aan het labelen van alle data, wat in dit geval kostbaar is, omdat het door experts gebeurd (Gal et al., 2017).
Naast Active Learning is synthesis geschikt voor het trainen van een classifier met beperkte data. Met synthesis kan in deze case de gelabelde data worden opgedeeld in meerdere data-elementen om de classifier te trainen. Helaas zijn hiervan geen voorbeelden beschikbaar in de literatuur.
Andere cases waarin Active Learning wordt toegepast in de zorg, zijn te vinden bij het ontwikkelen van medicijnen. Bij het ontwikkelen van medicijnen is het belangrijk om erachter te komen of een bepaald bestanddeel wel of niet reageert. Er zijn maar weinig beschikbare data, vaak slechts enkele bestanddelen waarvan bekend is dat ze reageren. Er zijn iets meer bestanddelen waarvan bekend is dat ze niet reageren en een overgrote meerderheid met ongelabelde bestanddelen. Het doel is om efficiënt actieve bestanddelen te vinden. Dit kan gedaan worden door een expert, maar ook door een algoritme waar Active Learning wordt toegepast (Warmuth et al., 2003). Door het toepassen van Active Learning, blijkt de kans groter dat een juiste keuze wordt gemaakt en een getest bestanddeel ook daadwerkelijk blijkt te reageren. Ook meer recente studies tonen aan dat het gebruik van verschillende Active Learning technieken — afhankelijk van de complexiteit van het vraagstuk — kwaliteit en kostenbesparing opleveren (Reker & Schneider, 2015).
Door het toepassen van Active Learning kon met alleen maar 100 datapunten toch een betrouwbare classifier gebouwd worden
Patiënt centraal
De toepassingen die hierboven staan beschreven, zijn vooral kleine nichegebieden waar de patiënt zelf niet direct veel van merkt. Uiteindelijk gaat het om de vraag hoe we de patiënt centraal stellen met data. De afbeelding hieronder laat zien wat er van een patiënt potentieel aan data beschikbaar is (Hansen et al., 2014).
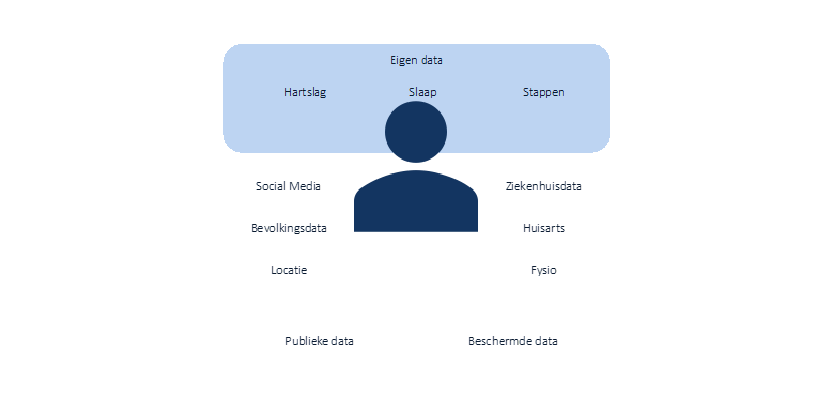
Figuur 1: Patiënt en de beschikbare data
De meest interessante toepassing die nu haalbaar is, ligt in de grote hoeveelheid data die een persoon of patiënt tegenwoordig zelf verzameld met smartwatches en smartphones. Het labelen van deze data is lastig, omdat personen zelf niet weten hoe bepaalde metingen medisch moeten worden geïnterpreteerd (Hansen et al., 2014). Active Learning kan een belangrijke rol spelen bij het ontsluiten van dit soort data. Hierdoor kunnen apps getraind worden om accuraat te voorspellen of iemand ziek wordt. Daarnaast is het van belang om hierbij de patiënt centraal te stellen (Sacristán & Dilla, 2015). Hypothetisch gezien bereiken we dit door te kijken naar de Active Learning technieken die worden toepast in aanbevelingssystemen. In die systemen kunnen algoritmes met weinig data goed gepersonaliseerd adviseren. Vergelijkbare technieken kunnen ook gebruikt worden om de zelf verzamelde data van een persoon te interpreteren. Hier kunnen waardevolle inzichten uit komen.
De beschermde data (aan de rechterkant van de afbeelding) zijn momenteel helaas nog slecht bereikbaar. De data zijn beschermd door een grote hoeveelheid regels, zoals privacyregels. Daarnaast zijn de data slecht bereikbaar, omdat elke instantie zijn eigen standaard gebruikt. Dit maakt de analyse lastig. De publieke data (aan de linkerkant van de afbeelding) kunnen worden gebruikt om de beschermde data te verrijken. Echter, dan moet eerst toegang tot de data geregeld zijn.
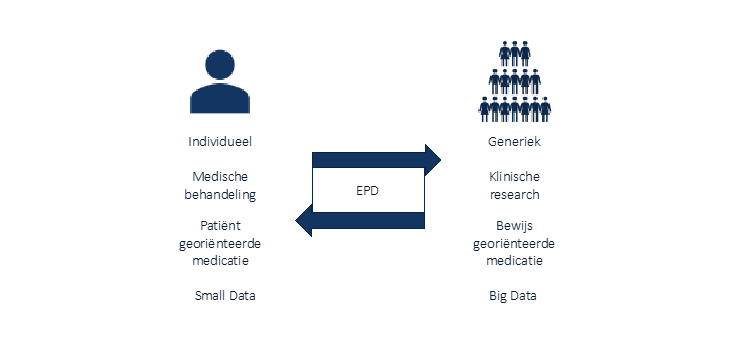
Figuur 2: EPD is een belangrijke voorwaarde voor Machine Learning
EPD
Het belang van een Elektronisch Patiënten Dossier(EPD) wordt door meerdere bronnen genoemd als een belangrijke voorwaarde voor AI en Machine Learning en wordt geïllustreerd in de afbeelding hierboven (Hansen et al., 2014; Sacristán & Dilla, 2015). Het EPD is de schakel tussen de Small Data bij de patiënt en de informatie die over de gehele populatie beschikbaar is aan de kant van de Big Data. Als deze beide kanten worden gecombineerd ben je in staat om alle informatie optimaal te analyseren en waarde te creëren voor de patiënt. Een goed werkend EPD hebben we in Nederland nog niet. Data-uitwisseling tussen zorg instanties onderling is al een groot probleem, laat staan dat de data beschikbaar gemaakt worden voor analyse.
Zo krijgen bijvoorbeeld topsporters gepersonaliseerde aanbevelingen over fitheid
Aanbeveling
Small Data en Active Learning technieken kunnen nu al voor interessante inzichten zorgen en de zorg actief verbeteren voor de individuele patiënt. Ook zonder een goed werkend EPD. We zien dat Active Learning op kleine schaal wordt toegepast op specifieke gebieden in de zorg. Hier kan waarde uit gehaald worden, maar de patiënt zal hier niet direct zelf wat van merken. Het gebrek aan een goed EPD blijft een beperking waar hard aan gewerkt moet worden in de komende jaren. Om in de tussentijd toch snel en veel waarde te leveren voor de patiënt, adviseren we om Active Learning technieken die worden ingezet bij aanbevelingssystemen toe te passen op alle data die een persoon of patiënt zelf verzamelt. De Active Learning technieken voor aanbevelingssystemen zijn specifiek gebouwd om met weinig beschikbare data om te gaan en individuele aanbevelingen te doen. Zo krijgen bijvoorbeeld topsporters gepersonaliseerde aanbevelingen over fitheid. Met hartslagmetingen en data van trainingen wordt bij hen gekeken naar belastbaarheid en risico om ziek te worden. Dit in tegenstelling tot vergelijkbare hartslagen voor een recreatieve sporter, daar betekenen de meting wat anders. Dus voor de topsporter en de recreant worden andere aanbevelingen of voorspellingen gegeven. Deze individuele gegevens moeten bij analyse daarom van elkaar gescheiden worden en niet op een grote hoop komen zoals bij andere Big Data-oplossingen.

Deze personalisatie ontbreekt in de zorg en is precies waar voorgaande systemen op hebben gefaald. Wij zien daarmee een krachtige toepassing van Smart Wearables die helpen met het verzamelen van data. Met Active Learning kunnen deze data nu al worden ingezet om meteen waarde te leveren voor de patiënt. Wij gaan graag in discussie over welke kansen u nog meer ziet met behulp van Active Learning en Small Data, neemt u gerust contact met ons op!
Referenties
- Gal, Y., Islam, R., & Ghahramani, Z. (2017). Deep Bayesian Active Learning with Image Data.
- Hansen, M. M., Miron-Shatz, T., Lau, A. Y. S., & Paton, C. (2014). Big Data in Science and Healthcare: A Review of Recent Literature and Perspectives Contribution of the IMIA Social Media Working Group. Yearb Med Inform, 21–27. https://doi.org/10.15265/IY-2014-0004
- Hu, G., Peng, X., Yang, Y., Hospedales, T. M., & Verbeek, J. (2018). Frankenstein: Learning Deep Face Representations using Small Data.
- Kitchin, R., & Lauriault, T. P. (2015). Small data in the era of big data. https://doi.org/10.1007/s10708-014-9601-7
- Lee, W.-S., Ahn, S. M., Chung, J.-W., Kim, K. O., Kwon, K. A., Kim, Y., … Baek, J.-H. (2018). Assessing Concordance With Watson for Oncology, a Cognitive Computing Decision Support System for Colon Cancer Treatment in Korea. JCO Clinical Cancer Informatics, (2), 1–8. https://doi.org/10.1200/cci.17.00109
- Lewis, D. D., Gale, W. A., Croft, I. W. B., & Van Rijsbergen, C. J. (1994). A Sequential Algorithm for Training Text Classiiers. Springer-Verlag.
- Reker, D., & Schneider, G. (2015). Active-learning strategies in computer-assisted drug discovery. Drug Discovery Today, 20(4), 458–465. https://doi.org/10.1016/j.drudis.2014.12.004
- Rubens, N., Kaplan, D., Sugiyama, M., Kantor, B., Ricci, F., Rokach, L., & Shapira, B. (2011). Active Learning in Recommender Systems. https://doi.org/10.1007/978-0-387-85820-3_23
- Sacristán, J. A., & Dilla, T. (2015, December 1). No big data without small data: Learning health care systems begin and end with the individual patient. Journal of Evaluation in Clinical Practice, Vol. 21, pp. 1014–1017. https://doi.org/10.1111/jep.12350
- Settles, B. (2009). Computer Sciences Department Active Learning Literature Survey.
- Strickland, E. (2019). How IBM Watson Overpromised and Underdelivered on AI Health Care. Retrieved from https://spectrum.ieee.org/biomedical/diagnostics/how-ibm-watson-overpromised-and-underdelivered-on-ai-health-care
- Suwanvecho, S., Suwanrusme, H., Sangtian, M., Norden, A. D., Urman, A., Hicks, A., … Kiatikajornthada, N. (2017). Concordance assessment of a cognitive computing system in Thailand. Journal of Clinical Oncology, 35(15_suppl), 6589–6589. https://doi.org/10.1200/jco.2017.35.15_suppl.6589
- Warmuth, M. K., Liao, J., Rätsch, G., Mathieson, M., Putta, S., & Lemmen, C. (2003). Active Learning with Support Vector Machines in the Drug Discovery Process ‡. https://doi.org/10.1021/ci025620t
- Wärnling, O., Bissmark, J., & Skolan, K. (2017). The Sparse Data Problem Within Classification Algorithms The Effect of Sparse Data on the Naïve Bayes Algorithm. Retrieved from www.kth.se