Interpreteerbare AI als oplossing voor het Black Box Probleem: van paper naar demo (deel 2/2)

In mijn vorige blogpost heb ik de noodzaak van Interpretable Artificial Intelligence toegelicht en zijn de eerste stappen gezet richting een systeem dat op een voor mensen te begrijpen manier voorspellingen kan doen. Er is een Azure Machine Learning Workspace opgezet waarin de dataset is opgeslagen en er is bovendien een trainingsrun uitgevoerd waarvan het model is opgeslagen in de workspace. Heb je de eerste blogpost gemist? Lees hem dan hier terug.
In deze blogpost gaan we verder met waar we bij mijn vorige post gebleven zijn. Wat er nog rest is dat het model gevalideerd moet worden en er een inference pipeline moet worden gebouwd zodat de uitkomsten van het model gebruikt kunnen gaan worden in een demo applicatie. Tussendoor geef ik tips waar je rekening mee kunt houden, zodat je deze kunt gebruiken bij je eigen projecten.
Validatie en inference
Nadat ik een model had getraind met redelijke validation accuracy, wilde ik valideren of het model daadwerkelijk goede voorspellingen kon doen op ongeziene test data en deze voorspellingen ook goed kon uitleggen. Bovendien moesten de voorspellingen en explanations verder worden uitgelegd op basis van visual characteristics van prototypes volgens de methode van This Looks Like That, Because … Explaining Prototypes for Interpretable Image Recognition. Omdat de code in eerste instantie bestond uit losse scripts die handmatig achter elkaar uitgevoerd moesten worden, bestond validatie aanvankelijk uit het uitvoeren van deze scripts voor meerdere test images. Nadat uitkomsten logisch leken en het model dus valide output leek te geven, heb ik deze tussentijdse uitkomsten opgeslagen zodat ik deze kon vergelijken met tussentijdse uitkomsten in het geval ik de code nog zou refactoren.
 Tip: in het geval code gerefactord moet worden, sla dan output op voordat je de refactoring toepast en vergelijk deze met de output nadat de refactoring is uitgevoerd.
Tip: in het geval code gerefactord moet worden, sla dan output op voordat je de refactoring toepast en vergelijk deze met de output nadat de refactoring is uitgevoerd.
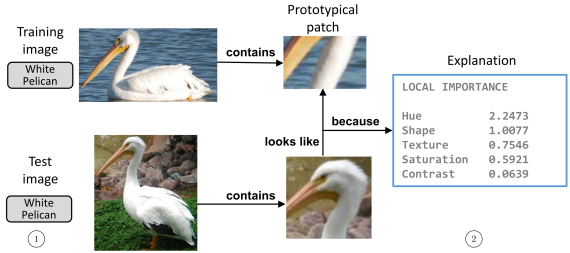
Uiteindelijk werken we toe naar een demo die aan de hand van 1 input image een voorspelling en uitleg daarvan kan geven die lijkt op figuren in het originele paper zoals hieronder. Om dit te kunnen doen, moesten er nog enkele stappen worden genomen:
- Inference code die voorspellingen maakt moest worden gerefactord zodat deze in een pipeline kon worden gebruikt. Bovendien was niet ieder deel van het oorspronkelijke script nodig.
- Output van de inference code (voorspelde klasse en explanations) moest kunnen worden gebruikt als input voor code die explanations verder uitlegt met visual characteristics zoals hue en contrast.
- Het geheel aan output van beide scripts moest worden gebundeld in een output image.
- Het totaal aan scripts moest worden gebundeld in een inference pipeline.
Net als bij het opzetten van het experiment, heb ik bij het opzetten van de inference pipeline van voor naar achter gewerkt. Tussendoor was het belangrijk om regelmatig de uitkomsten van de pipeline te verifiëren aan de hand van de tussentijdse resultaten die ik van tevoren met de niet gerefactorde code had opgeslagen. Op die manier kwam ik er bijvoorbeeld achter dat er verschillen optraden doordat ik in mijn pipeline tussentijdse resultaten niet opsloeg in JPEG files en dat in de originele code wel gebeurde. Dit heb ik opgelost door bepaalde libraries er uit te halen of desnoods resultaten tijdelijk op te slaan in temporary files met de tempfile library in Python. Het resultaat van deze werkzaamheden was dat ik een pipeline had die gebruikt kon worden om inference te doen op een nieuwe test image. Op die manier kon ik het model nog verder valideren en bovendien kon ik delen van het script in de volgende stap gebruiken tijdens de deployment van een model.
Tip: Verifieer de resultaten tijdens het bouwen van een pipeline tussentijds, zodat je precies weet waar een probleem zit wanneer er iets mis gaat.
Deployment
Om een model te kunnen deployen, is er een entry script nodig dat aan de hand van een deployment configuration en een inference configuration een scoring script aanroept. Met deze configuraties kun je aangeven in wat voor soort Docker container gedraaid moet worden en of de deployment lokaal of in de cloud moet worden gedaan. Het scoring script laadt vervolgens het getrainde model en maakt een voorspelling op een nieuwe test image. Meer informatie over deployment is hier te vinden. Het handigst is hierbij om eerst een lokale deployment op te zetten, zodat alles snel getest kan worden en niet direct de overhead van het opzetten van een deployment in de cloud er bij komt kijken.
Tip: ga bij het opzetten van een deployment van een model eerst uit van een lokale deployment.
Bij de inference configuration ben ik uit gegaan van een curated inference environment welke ik heb uitgebreid met enkele dependencies die ik bij mijn eigen project nodig had. Deze konden worden meegegeven door een requirements.txt file op te geven. Meer informatie hierover is hier te vinden.
Het scoring script kon ik grotendeels baseren op de inference pipeline die geschreven was in de vorige stap. Deze zorgde er immers al voor dat aan de hand van een input test image en een model, een voorspelling en de uitleg daarvan wordt gegeven. Wat hier vooral nog bij moest worden aangepast was dat er niet een path naar een test image, maar een test image als binary data als input kon worden gegeven. Dit kon worden gedaan door als input voor het script een AMLRequest te accepteren dat binary data bevat. Documentatie hierover is hier te vinden. Verder is uitgangspunt dat we toe werken naar een demo applicatie die de output van de deployment kan tonen. Om de output van de deployment naar de demo applicatie te krijgen, heb ik ervoor gekozen om als output de top 3 explanations van het model te uploaden naar een blob storage en URLs naar de output samen met de voorspelde klasse en de echte klasse (a.d.h.v. de filename) met de demo applicatie te delen zodat de demo applicatie dit als output kan tonen. Om dit in te regelen, heb ik een connection string van de betreffende blob storage in de omgevingsvariabelen van de deployment gezet zodat output geüpload kan worden.

Overzicht van informatie die van de deployment naar de demo applicatie gaat
Het instellen van de deployment heb ik kunnen doen aan de hand van dit artikel. Verder is dit notebook een erg handig startpunt geweest omdat hier stap-voor-stap een lokale deployment wordt opgezet. Eerst worden de verschillende configuraties ingesteld, vervolgens wordt het scoring script geschreven en daarna wordt de lokale deployment gestart. Tot slot wordt er code gegeven waarmee de deployment gestart kan worden in een cloud omgeving, maar hier heb ik uiteindelijk geen gebruik van gemaakt. Mocht er iets worden aangepast in het scoring script, dan kan de lokale deployment gemakkelijk gereload worden. Op die manier is het niet nodig om de volledige deployment opnieuw uit te voeren en dit versnelt de development cycle.
» Tip: Gebruik dit notebook als startpunt bij het opzetten van een lokale deployment, omdat hiermee snel een lokale deployment getest en verbeterd kan worden.
Belangrijk is bij het instellen van de deployment dat je opnieuw terug gaat naar de testdata uit vorige stappen en controleert of de output van de deployment is wat je ervan verwacht. Zo kwam ik er bijvoorbeeld achter dat de imload methode van Pillow andere resultaten geeft tijdens deployment vanwege een verschil tussen een Unix omgeving (Docker container) en mijn Windows omgeving (zie hier). Het ombouwen van deze functionaliteit en het gebruik van OpenCV’s imread methode heeft me daarbij geholpen.
Tip: Valideer je deployment aan de hand van testdata uit eerdere stappen, zodat je weet dat de deployment zich gedraagt zoals je verwacht.
Doet de deployment wat je ervan verwacht, dan kan de code die in het notebook staat worden omgezet naar een losstaand deployment script zodat niet de cellen in het notebook maar een Python script kan worden gedraaid om deployment te starten.
In mijn project heb ik er uiteindelijk niet voor gekozen om over te gaan tot deployment in een cloud omgeving. De scope van het project was om lokaal een demo te kunnen draaien en daarom was een lokale deployment afdoende. Het aanpassen van de deployment configuration zou echter voldoende moeten zijn om de deployment daadwerkelijk in de cloud te doen.
Demo
Als het goed is, is het tot nu toe mogelijk om het getrainde model lokaal te deployen, een testplaatje naar het endpoint toe te sturen en vervolgens URLs die wijzen naar de top 3 explanations samen met een voorspelde klasse en de werkelijke klasse daarvan terug te krijgen. Een explanation van het model kan vervolgens getoond worden door naar een van de URLs te gaan die als output wordt gegeven en daar de explanation te downloaden. Wat er in de demo applicatie moet worden gedaan is dat het proces waarin een input image wordt opgestuurd naar de deployment en de output wordt gedownload en wordt getoond, samen worden gevoegd in een applicatie.
Met het framework Flask heb ik redelijk snel een kleine applicatie op weten te tuigen waarin via een input veld via een HTTP POST request een image kan worden geüpload naar het gedeployde model. De output wordt vervolgens gedeserialiseerd tot de echte klasse, de voorspelde klasse en drie URLs naar explanations en dit geheel wordt getoond in een output scherm. Tot slot heb ik Bootstrap in de applicatie geïntroduceerd om de applicatie er op een simpele manier wat gelikter uit te laten zien. Het eindresultaat is hieronder te zien.
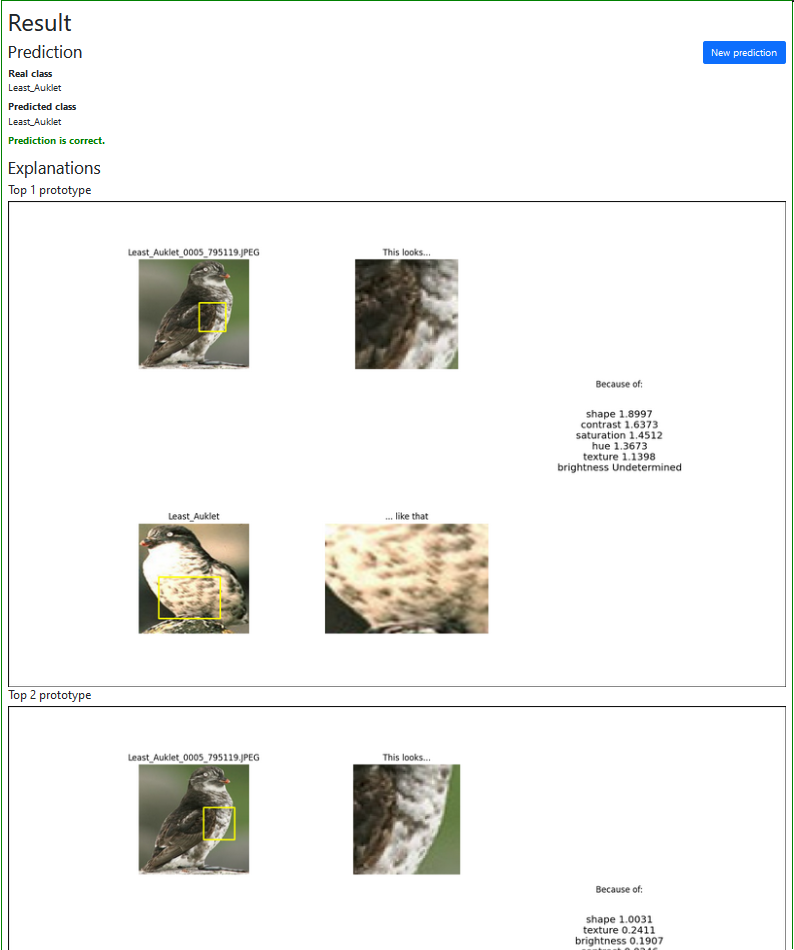
Screenshot uit de demo applicatie
Nu het volledige systeem staat, is het getrainde model gemakkelijk te controleren op of deze de juiste keuzes maakt vanwege de juiste redenen. In het voorbeeld hierboven is duidelijk te zien dat het model zijn voorspelling baseert op het feit dat de borst van de vogel in de test image overeen komt met de borst van eenzelfde soort vogel die het tijdens training heeft gezien. Dit is daarom een juiste voorspelling met de juiste redenen.
In het onderstaande voorbeeld is te zien dat het model het echter niet altijd goed doet. Zoals bovenaan in de demo te zien is, is de voorspelling weliswaar correct (black footed albatross), maar wanneer je de uitleg van de keuze bekijkt, is te zien dat het model deze keuze baseert op het feit dat de achtergrond in de test image overeen komt met de achtergrond van dezelfde soort vogels die tijdens training zijn gezien. Dit is precies waar de kracht van Interpretable AI te zien is omdat je op deze manier na kunt gaan wat de redenering van het model is geweest. Met een black box model zou dit voorbeeld alleen worden geteld als een juiste voorspelling, maar met deze techniek is goed te zien dat het maken van de voorspelling eigenlijk fout gaat.
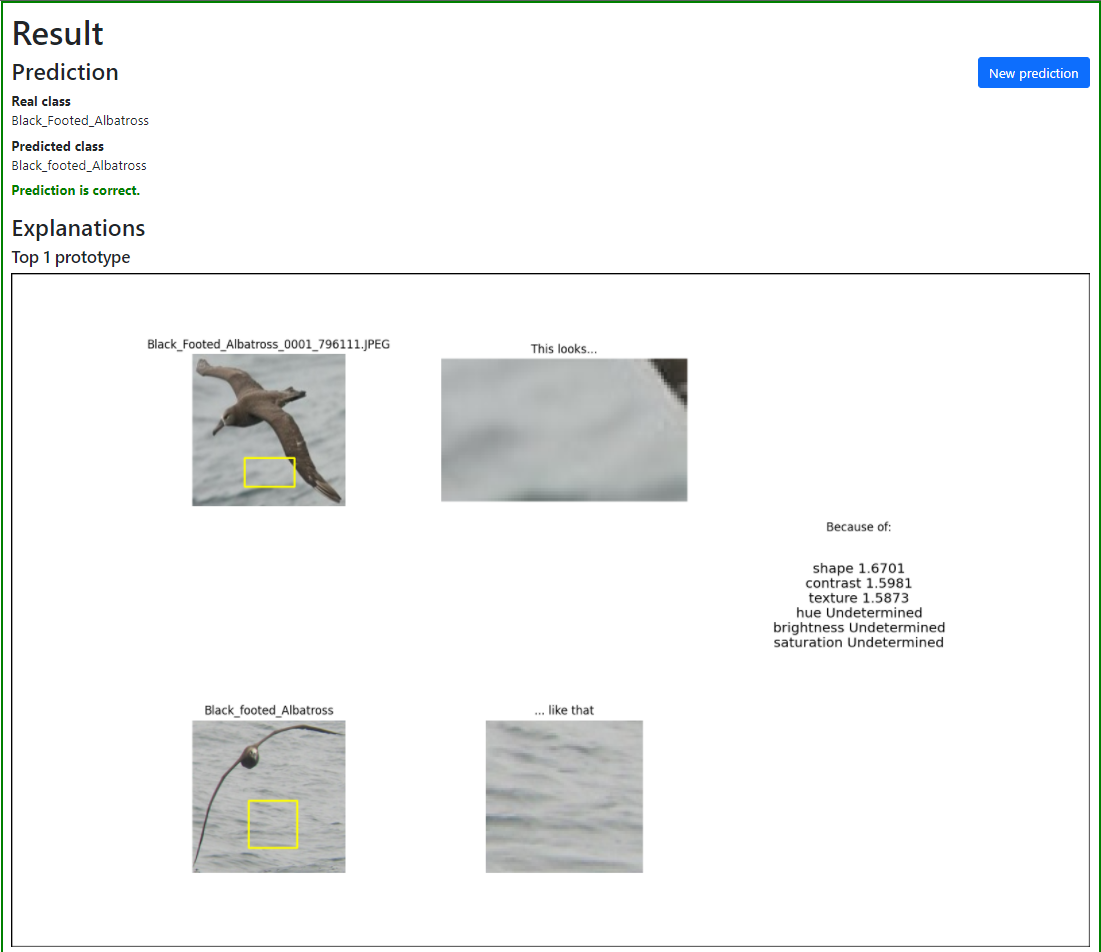
Voorbeeld van een juiste voorspelling vanwege onjuiste redenen
Wordt er vervolgens een test image aan het model getoond waarin een ander soort vogel met eenzelfde soort achtergrond als in het voorbeeld hierboven te zien is, dan wordt de verkeerde voorspelling gedaan omdat het model focust op de verkeerde delen van een afbeelding. Omdat we bovenstaande uitleg hebben gezien, begrijpen we nu waarom de voorspelling hieronder fout wordt gedaan. Zie het voorbeeld hieronder.
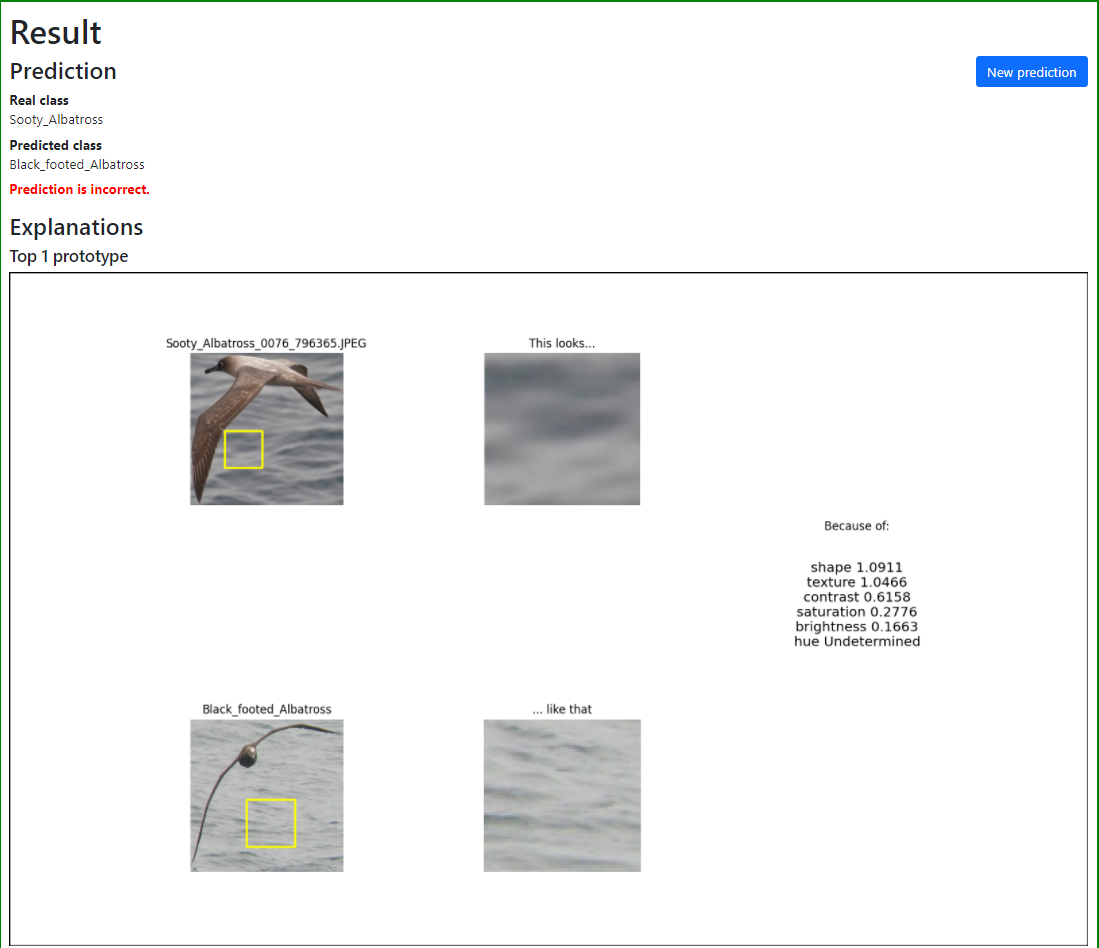
Voorbeeld van een foute voorspelling vanwege onjuiste redenen
Conclusie
Bij het gebruik van Artificial Intelligence is het belangrijk dat de keuzes die door een model worden gemaakt, uitgelegd kunnen worden. Op die manier kan het systeem worden gecontroleerd en daardoor makkelijker worden vertrouwd. In deze serie van twee blogposts heb ik middels een casus in Interpretable AI de potentie van deze techniek laten zien en heb ik getoond hoe je van het lezen van een paper kunt komen tot een werkend en gedeployd model dat kan worden gebruikt in een demo applicatie.
Wil je snel resultaat? Zorg er dan voor dat je je experiment in eerste instantie klein maakt. Probeer zo snel mogelijk lokaal de pipeline aan de praat te krijgen en bouw vervolgens uit tot de gewenste grootte. Op die manier houd je de feedback loop zo kort mogelijk en kun je problemen vlug oplossen.
Ik hoop dat je bij je volgende experiment wat hebt aan de tips die ik heb gegeven! Heb je vragen, laat hieronder gerust een reactie achter of stuur me een e-mail.