Naarmate Artificial Intelligence (AI) steeds verder doordringt in kritieke gebieden, zoals de gezondheidszorg, de overheid en de financiële sector, lijkt het onvermogen van mensen om deze modellen te begrijpen problematisch. Uitleg en interpreteerbaarheid van die modellen kan een remedie zijn, maar wat deze termen betekenen en waarom het belangrijk is, wordt maar weinig uitgelegd. In dit artikel duiken we diep in de uitleg van AI-modellen en de mogelijkheid om deze te interpreteren.
AI kan niet meer zonder uitleg

Dit artikel is onderdeel van een driedelige serie. Meer informatie over de modellen is terug te vinden in het artikel: Interpretable AI en Explainable AI.
Verplichting van uitleg
AI en Machine Learning (ML)-modellen hebben een groot potentieel om producten en diensten te verbeteren. Maar als deze modellen geen uitleg geven over hun uitkomsten, dan kan deze ondoorzichtigheid een obstakel zijn die het gebruik van machine learning belemmert. Het onvermogen van mensen om de uitkomsten te begrijpen moet daarom doorbroken worden. Er is een toenemende behoefte aan interpreteerbaarheid, transparantie en begrijpelijkheid van AI-systemen.
Zonder de uitleg van een AI-model en de beslissingen die het neemt, bestaat het risico dat het model niet als betrouwbaar wordt beschouwd. Een goede uitleg kan de benodigde begrijpelijkheid en transparantie om meer vertrouwen in op AI gebaseerde oplossingen mogelijk maken. Uitleg wordt een cruciaal onderdeel voor de praktische inzet van AI-modellen. Want wie al gestart is met AI of wie ermee wil starten kan zich niet onttrekken aan de verplichting om uitleg te geven over de uitkomsten van haar model. Niet alleen vanuit professioneel oogpunt is het nodig om met uitleg modellen transparant te maken, ook vanuit de wetgeving wordt deze noodzaak strikter. Het is zelfs nodig om te voldoen aan de grondrechten van AI-gebruikers met betrekking tot de uitkomsten van een AI-systeem.
Wetgeving maakt het noodzakelijk
Binnen de Europese Unie is nieuwe regelgeving in de maak voor handhaving, om ongewenste resultaten van AI-systemen te voorkomen. Gesteld wordt dat: “ondoorzichtigheid van veel algoritmen tot onzekerheid leiden en een obstakel vormen voor de effectieve handhaving van de bestaande wetgeving inzake veiligheid en grondrechten.” Strenge eisen worden vooral gesteld aan AI-systemen die vallen binnen het risiconiveau ‘Hoog’. Dit zijn een beperkt aantal AI-systemen. De grote meerderheid van de huidige AI-systemen die op dit moment in de EU worden gebruikt, behoren tot het risiconiveau ‘Minimaal risico’. Deze systemen kunnen conform de bestaande wetgeving worden ontwikkeld en gebruikt.
Dat betekent nog steeds niet dat een AI-systeem met minimaal risico geen uitleg hoeft te geven over haar uitkomsten. Eén van de bestaande wetten is de privacywet. Deze wet geeft je het recht op een menselijke blik bij automatische besluiten die over je gaan en die gevolgen voor je hebben. Bijvoorbeeld wanneer je een lening niet krijgt, of niet voor een sollicitatiegesprek wordt uitgenodigd, moet de organisatie een nieuw besluit nemen waarbij een mens je gegevens beoordeelt. Voor een AI-systeem betekent dit dat duidelijk moet zijn hoe de conclusie tot stand is gekomen. Het AI-model zal dus uit moeten leggen hoe zij tot het resultaat is gekomen.
Vinden van fouten
Uiteraard zijn er ook AI-systemen die vanuit een wettelijk kader geen uitleg hoeven geven. Dit gaat om AI-systemen die geen personen treffen, of systemen die geen juridisch effect hebben op personen. Denk hierbij aan marketingsystemen die doelgroepen bepalen met machine learning of aanbevelingen voor muziek of films.
Zoals eerder gesteld, kies je vanuit professioneel oogpunt toch voor uitleg van resultaten bij een dergelijk AI-systeem. Als ontwerper van het AI-systeem wil je fouten kunnen vinden. Als je systeem ondoorzichtig is en je de redenatie van je model niet kunt volgen, weet je niet welke aanpassingen je moet doen om ongewenst gedrag te voorkomen. Het kan zelfs zo zijn dat een AI-systeem met schijnbaar goede uitkomsten komt, maar dat deze zijn gebaseerd op verkeerde redenaties. Een bekend voorbeeld is dat een AI husky’s herkende op basis van de sneeuw op de achtergrond. Dit soort fouten wil je ook kunnen ontdekken, want als je een AI-systeem beter begrijpt dan leidt dat uiteindelijk tot betere resultaten. Dit is nog een voorbeeld waarbij de consequenties niet zo groot zijn.
Maar wat als een verkeerde redenatie leidt tot een verkeerde diagnose voor bijvoorbeeld een longontsteking? Caruana et al. (2015) beschrijven een model dat is getraind om de kans op overlijden door longontsteking te voorspellen en dat minder risico toekent aan patiënten als ze ook astma hadden. In feite was astma voorspellend voor een lager risico op overlijden. Dit was te danken aan de agressievere behandeling die deze patiënten standaard kregen. Maar als het model zou worden ingezet om te helpen bij triage, zouden deze patiënten minder agressieve behandeling krijgen. Een zeer gevaarlijke en onwenselijke uitkomst.
Er zijn gevallen waar het AI-model met een eenvoudige tekstuele uitleg kan aangeven waar de uitkomst op gebaseerd is. Een bekend voorbeeld zijn de aanbevelingen voor series en muziek door streamingdiensten. Netflix geeft hier een voorbeeld van in de afbeelding.
Vertrouwen
Voor de adoptie van nieuwe AI-systemen is vertrouwen ook belangrijk. De professionals die gebruikmaken van het AI-systeem moeten de uitkomsten kunnen vertrouwen. Denk daarbij aan bijvoorbeeld artsen en patiënten. Als je niet weet hoe het model aan de uitkomsten komt, dan zijn deze lastig te vertrouwen. Kortweg gezegd zijn er vijf belangrijke redenen waarom een AI-systeem uitleg moet geven over de uitkomsten van haar model:
- Wet- en regelgeving
- Vertrouwen in de uitkomsten
- Vinden van fouten
Vragen die beantwoord worden door de uitleg van AI
De uitleg van een AI-systeem hebben we dus nodig voor verschillende redenen. Maar uitleg geef je niet zomaar, daar liggen vragen aan ten grondslag. De vragen waarop antwoord gegeven kan worden zijn:
- Waarom voorspelt het model deze uitkomst?
- Welke factoren hebben een significante impact op het besluit?
- Wat moet je veranderen om een andere uitkomst te krijgen?
- Aan welke condities moet worden voldaan om de huidige uitkomsten te behouden?
- Wat gebeurt er wanneer de gegevens wijzigen?
Hoe ziet de uitleg eruit? Een praktijkvoorbeeld
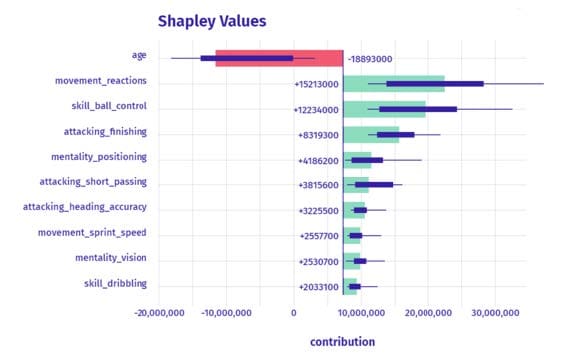
De vorm waarin uitleg wordt gegeven hangt af van de gebruikte techniek. Eén van die vormen is het gebruik van Shapley Values. Dit is een manier om uit te drukken welke factoren de grootste invloed hebben gehad op de uitkomst van een voorspelling. Laten we kijken hoe uitleg eruit kan zien aan de hand van een voorbeeld. Met de data uit het spel FIFA-20 kan een model gemaakt worden die de waarde van een speler in het spel voorspelt. De voorspelde waarde van Cristiano Ronaldo is €32,6 miljoen. De vraag is dan hoe dit bedrag tot stand is gekomen en welke factoren voor deze voorspelling hebben gezorgd.
In onderstaande grafiek zien we de uitleg van de voorspelling van zijn waarde. We zien welke factoren een negatieve invloed hebben op de voorspelling. Dat wil zeggen, deze zorgen voor een lagere waarde van de speler. En we zien de factoren die een positieve invloed hebben op de voorspelde waarde. Als we kijken naar de voorspelling van de waarde van Cristiano Ronaldo, dan zien we dat zijn leeftijd een negatieve invloed heeft op zijn waarde (- €18.893.000). Alle overige factoren, zoals movement reactions (+€15.213.000) en skill ball control (+€12.234.000) dragen alleen maar bij aan zijn waarde.
Dit artikel is onderdeel van een driedelige serie. In de volgende artikelen komen Interpretable AI en Explainable AI en Checklist: Hoe kies je tussen Interpretable AI en Explainable AI? aan bod. Joop legt uit hoe deze modellen leren en uitgelegd kunnen worden.