Synthetische data, onterecht bestempeld als ‘nepinformatie’, is kunstmatig gegenereerd en niet gebaseerd op echte gebeurtenissen. Toch is het waardevol, vooral bij het ontwikkelen van applicaties en het trainen van machine learning-modellen. Het biedt het voordeel van het anonimiseren van productiedata voor testdoeleinden en het uitbreiden van bestaande datasets met nieuwe data. Hoe werkt het en wat zijn de voor- en nadelen?
De potentie en valkuilen van synthetische data

2030: Synthetische data > echte data
De hoeveelheid synthetische data in de wereld neemt exponentieel toe. Als we de voorspellingen van Gartner mogen geloven, dan gebruiken AI-modellen in 2030 meer kunstmatige data dan echte data.
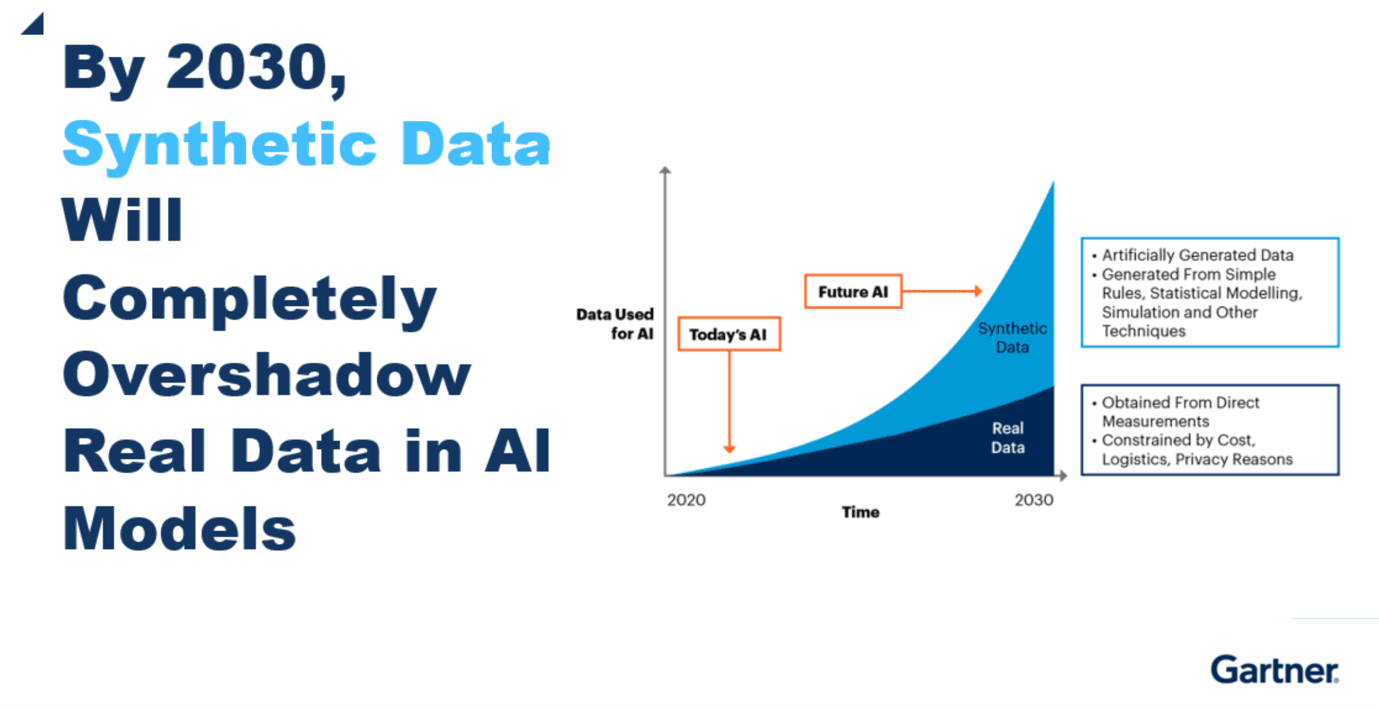
Die toename is best te begrijpen. Bij de ontwikkeling van software of machine learning-modellen is het belangrijk om te kunnen testen en daarvoor is veel data nodig. Productiedata is lang niet altijd geschikt om mee te testen, zeker niet als het gaat om persoonsgegevens die privacygevoelig zijn.
Hoe goed bootst synthetische data de echte wereld na?
Er zijn verschillende manieren om kunstmatige data te genereren. Het succes ervan valt of staat met de kwaliteit; hoe goed bootsen synthetische data eigenlijk (data uit) de echte wereld na? Als je gaat testen met kunstmatige data die niet lijkt op de echte data, ontstaan er al gauw problemen die kunnen leiden tot slecht presterende apps en systemen.
Een voorbeeld. Stel dat we een review-platform willen oprichten voor hotels, restaurants en bezienswaardigheden. Het succes van zo’n platform wordt bepaald door de kwaliteit van de ervaring die je kunt bieden; als gebruikers goede en relevante suggesties krijgen aangeboden, dan zullen ze de app vaker gebruiken, reviews invullen en het platform aanbevelen aan anderen.
Bij het ontwikkelen van het platform is het dus belangrijk om zo veel mogelijk data te verzamelen, zowel van aangesloten bedrijven, als reviews. Vervolgens moet je deze brondata goed aanbieden om de gebruikerservaring te optimaliseren. Daarvoor kun je onder meer ketentesten en regressietesten uitvoeren. Maar productiegegevens van gebruikers mag je niet zomaar gebruiken om te testen, zeker niet als het om persoonsgegevens.
Op basis van je echte datasets kun je synthetische data genereren die zo dicht mogelijk de werkelijkheid benadert. De namen van gebruikers, hun geboortedata, adres en ga zo maar door worden gefingeerd. Maar dat moet wel op zo’n manier gebeuren dat data ook realistisch zijn (en dus bruikbaar zijn om op te testen).
Dat is nog lastiger dan je zou denken. Stel, ons reviewplatform heeft vijf soorten horecagelegenheden: restaurants, clubs, cafés, hotels en fastfood. Als je een willekeurige verdeling gaat maken, dan zal waarschijnlijk elke categorie gemiddeld ongeveer 20 procent voorkomen. In werkelijkheid kan het best zo zijn dat je productiedata een hele andere verdeling laten zien, dat bijvoorbeeld ruim 50 procent van de aangesloten bedrijven in de categorie ‘restaurant’ vallen en dat slechts 2 procent ‘club’ is.
Nog een voorbeeld. Onder bezoekers van ‘echte’ clubs zijn de leeftijdscategorieën 18-25 en 25-35 jaar zwaarder vertegenwoordigd dan bijvoorbeeld 65-75 jaar. Als je die correlatie niet meegeeft aan het algoritme, dan krijg je een dataset die niet of nauwelijks bruikbaar is.
Club Havenzicht
Deze verbanden liggen misschien voor de hand en zijn relatief eenvoudig te verhelpen. Je kunt ook te maken krijgen met onrealistische data die lastiger te corrigeren is in een algoritme. Stel dat er in onze database een club voorkomt met de naam Havenzicht en een restaurant met de naam Galaxy; mensen voelen aan dat dit onrealistisch is, maar hoe vertel je dit aan een algoritme?
De kwaliteit van de data is dus sterk afhankelijk van de kwaliteit van de algoritmes die je gebruikt om data te genereren. De ervaring leert dat het best wat tijd kan kosten om het goed te doen, zeker als je te maken hebt met complexe datasets. Het is nu eenmaal ingewikkeld om met algoritmes de volledige complexiteit van de echte wereld na te bootsen.
Tools om kunstmatige data te genereren
Gelukkig zijn er verschillende tools die je hierbij kunnen helpen. Naarmate het gebruik van synthetische data toeneemt, groeit ook het aantal tools dat je kunt gebruiken om data te genereren.
De meest complete tools zijn over het algemeen helaas best kostbaar. Voorbeelden zijn Tonic, Hazyen en Mostly AI; ze presenteren zich als ‘all-in-one’ oplossingen die je kunnen helpen on data te anonimiseren en kunstmatige data te genereren.
Gelukkig zijn er ook minder kostbare oplossingen; basic tools waar je zelf mee aan de slag kunt. Faker is een Python package dat nepdata voor je genereert (zoals willekeurige persoonsgegevens en bedrijfsnamen), maar je kunt er ook stress-testen mee uitvoeren of data anonimiseren. Ook kun je zelf een combinatie van persoonsgegevens doorgeven.
Er zijn ook tools die niet alleen helpen bij het genereren van data, maar ook bij het controleren of data realistisch is. Een voorbeeld hiervan is Data Synthetizer. Deze tool kun je gebruiken om kunstmatige (geanonimiseerde) data te genereren op basis van bestaande datasets. Eerst worden data geanalyseerd om er zeker van te zijn dat de synthetische data de juiste distributie en correlatie heeft. Nadat de data daadwerkelijk is gegenereerd, vergelijkt de tool deze ook nog met echte data om zo de betrouwbaarheid te toetsen. Synthetic Data Vault is een vergelijkbare tool die ongeveer hetzelfde kan.
Kortom: hoewel synthetische data veel kansen bieden, is het vooralsnog geen heilige graal. En als je er gebruik van maakt, is het nog niet eenvoudig om dit op de juiste manier te doen. Er zijn tools die daarbij kunnen helpen. Ze bieden vaak veel functionaliteit, maar kunnen vrij kostbaar zijn. Zelf tooling ontwikkelen is een mogelijk goedkopere optie, maar als je veel functionaliteit wilt hebben, dan kan dit best wel veel tijd kosten.
De ervaring leert dat samenwerking hierin met een domeinexpert helpt om de kwaliteit naar een hoger niveau te krijgen. Deze experts kunnen wijzen op verbanden die je zelf misschien niet had gezien – zoals een club die Havenzicht heet.
Synthetische data geen heilige graal
Kortom: hoewel synthetische data veel kansen bieden, is het vooralsnog geen heilige graal. En als je er gebruik van maakt, is het nog niet eenvoudig om dit op de juiste manier te doen. Er zijn tools die daarbij kunnen helpen. Ze bieden vaak veel functionaliteit, maar kunnen vrij kostbaar zijn. Zelf tooling ontwikkelen is een mogelijk goedkopere optie, maar als je veel functionaliteit wilt hebben, dan kan dit best wel veel tijd kosten.
De ervaring leert dat samenwerking hierin met een domeinexpert helpt om de kwaliteit naar een hoger niveau te krijgen. Deze experts kunnen wijzen op verbanden die je zelf misschien niet had gezien – zoals een club die Havenzicht heet.