Van DataOeps naar DataOps door testen
Testen in Dataprojecten
In Data Engineering is het gebruik van geautomatiseerde testen geen gewoonte. Als Data Engineer is dit wel belangrijk, omdat testen fouten voorkomen en herleidbaarheid van fouten vergroot. Minder fouten maakt het hele Data Engineering proces efficiënter en effectiever, waardoor de Data Engineer meer waarde creëert. In dit artikel leggen we uit hoe testen jou als Data Engineer verder gaat helpen om tot een echte DataOps mindset te komen.
Data Engineers kunnen kijken naar softwareontwikkeling, waar het uitgebreid testen van software met geautomatiseerde testen, de normaalste zaak van de wereld is. Deze testen voorkomen ongewenste en onverwachte bugs en verhogen daarmee de kwaliteit van het geleverde product. Dit is een van de fundamenten waar DevOps op steunt. DevOps is een methode van softwareontwikkeling waarbij een team de verantwoordelijkheid heeft voor zowel het ontwikkelen als het onderhouden van de software. Geautomatiseerd testen van de software is daarbij cruciaal om de kwaliteit goed te houden en te voorkomen dat er tijdens ontwikkeling fouten in de software sluipen.
Helaas is deze aanpak niet gebruikelijk in projecten die met data te maken hebben. Er bestaan wel concepten als Database DevOps, waarbij deployment van je database wordt gedaan vanuit DevOps tooling zoals Azure DevOps. Dat is een stap in de goede richting omdat bij elke deployment testen worden uitgevoerd, maar dan zijn we er nog niet. De principes van DataOps gaan over de gehele lifecycle van je data. Dat vereist een bredere blik dan alleen testen tijdens deployment en gaat daarmee dus verder dan DevOps. Maar waar moet je opletten in je reis naar adequate testen om tot een echte DataOps werkwijze te komen?
Waarom testen
Bij het ontwikkelen van software wordt een breed scala aan geautomatiseerde testen toegepast, denk aan unittesten, functionele testen, performance testen, load testen in geautomatiseerde pipelines die vast onderdeel zijn van de dagelijkse werkzaamheden. Bij data gerelateerde projecten wordt een compleet nieuw probleem geïntroduceerd. Op het deel dat je zelf in de hand hebt, namelijk de code, is het makkelijk om te testen op een vergelijkbare manier als bij het ontwikkelen van software. Maar bij data gerelateerde projecten komen er externe afhankelijkheden bij. Je bent afhankelijk van databronnen buiten jouw eigen team. Als er iets met die databronnen gebeurt, heeft dat invloed op jouw ETL, nauwkeurigheid van je modellen of op wat je BI-dashboard toont aan de gebruiker.
Bij software development weet je van tevoren wat de input is en daar stem je de testen op af, een Data Engineer is afhankelijk van externe databronnen waardoor de input opeens variabel is. Wordt er iets simpels als een kolomnaam aangepast, dan kan je hele oplossing omvallen. Als je de fout pas aan de gebruikerskant vindt, waar komt deze dan vandaan? Misschien is het toch iets dat je zelf geïntroduceerd hebt bij de ETL, misschien is het de business die op een andere manier data zijn gaan invoeren. Misschien is het een systeemupdate? Door deze onduidelijkheid ben je ontzettend veel tijd kwijt aan het fixen van bugs en achterhalen van de bron van veranderingen of problemen.
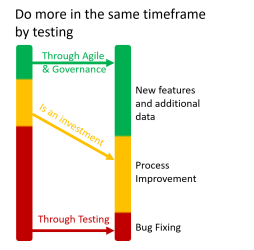
Dat kan beter: de DataOps methodieken bieden hier uitkomst voor. Het doel is om net zoals met DevOps meer hergebruik en een kortere time-to-market te realiseren. Testen is daarbij essentieel om impact te maken. De afbeelding hieronder vat het samen: goed testen voorkomt dat je veel tijd kwijt bent met bugfixen, maar het is wel een investering in het maken en continu verbeteren van de testen. Uiteindelijk zorgt de investering in betere testen en processen ervoor dat een team meer tijd kan besteden aan het opleveren van features en waarde.
Test Perspectief
We moeten niet alleen testen wat we bouwen zoals bij DevOps, maar ook testen wat we gebruiken, namelijk de data. Waarom doen we dit eigenlijk nog niet? Dit valt vooralsnog vaak buiten de ‘standaard testen’ om die we al gewend zijn om te doen. Vooraf lijkt dit een ontzettend grote berg werk omdat er in theorie zoveel getest kan worden. Dat is ook zo, in principe kan je oneindig doorgaan met het maken van testen op de data die je verwerkt. In de volgende hoofdstukken gaan we onze aanpak uitleggen waarmee je maximale efficiëntie haalt, zoveel mogelijk van de voordelen met zo min mogelijk werk vooraf. Belangrijk bij het maken van testen voor DataOps is om onderscheid te maken tussen de volgende 2 begrippen; Innovation Pipeline en Value Pipeline.
Innovation Pipeline
Stel dat we een nieuwe databron willen aansluiten. Om dat te doen, onderzoeken we wat er beschikbaar is aan data en wat de eindgebruiker precies nodig heeft. Zo weten we welke databronnen aangesloten moeten worden en wat voor transformaties eventueel nodig zijn. Dit is vergelijkbaar met software ontwikkelen, denk aan het bouwen van nieuwe functionaliteit. In de DevOps pipeline zitten veel geautomatiseerde testen zoals Unit Testen, Performance testen en integratie testen. Deze zorgen dat de software aan de eisen voldoet en blijft voldoen en voorkomt dat er fouten worden geïntroduceerd tijdens verdere ontwikkeling. Met dataprojecten kan je dat ook doen, maar daarvoor is het belangrijk om een vaste set aan data te hebben om op te testen. Als de data in de ontwikkelfase variabel zijn, weet je niet of een fout is geïntroduceerd door andere data of door de code. De data die we gebruiken blijven gelijk in de Innovation Pipeline, maar de code wijzigt. Zo kun je het daadwerkelijke effect van de aanpassingen van je code zien. In deze pipeline bevinden zich veel ‘traditionele’ DevOps tests zoals unittesten, performance testen en integratie testen.
Value Pipeline
De Value Pipeline wordt relevant in productie. We hebben uit de Innovation Pipeline een nieuwe implementatie gevonden die goed lijkt te werken. De werkelijkheid is weerbarstig, en we moeten goed in de gaten houden wat er door onze pipeline heen stroomt. We testen nu niet de code, die blijft ongewijzigd. We focussen op de variabele data in productie. Welke patronen verwachten we, wat zijn outliers, wat weten we van de structuur van de binnenkomende data waar we deze aan kunnen spiegelen, en dus testen op kunnen schrijven. Dat gaat ook over het wanneer van het ontvangen van nieuwe data, hoort dat elk uur te gebeuren? Wat betekent het als we de data niet ontvangen? Wat als de distributie van de data opeens anders is? Goede kans dat we dan willen ingrijpen omdat dat erg grote en mogelijk ongewenste invloed op je model kan hebben. Meten is weten. Veel vragen die heel specifiek zijn voor DataOps. DevOps beperkt zich tot de Innovation Pipeline omdat er geen sterke afhankelijkheden zijn van externe databronnen zoals bij DataOps projecten wel het geval is.
Testen uitvoeren
Er zijn veel mogelijkheden om te testen. In verschillende pipelines van een datastroom zijn andere testen nodig om tot een optimaal resultaat te komen. Bij elk van de tests die wordt gedaan, is het belangrijk om duidelijk te maken of een gevonden fout moet leiden tot uitval of tot een waarschuwing. Om dat te kunnen doen moet je eerst een risicoanalyse doen, die gebruik je om te kijken welke risico’s je afgedekt wil hebben met testen. Denk bij elke test die je schrijft ook na vanuit welk perspectief deze test geschreven wordt, de Innovation Pipeline of Value Pipeline?
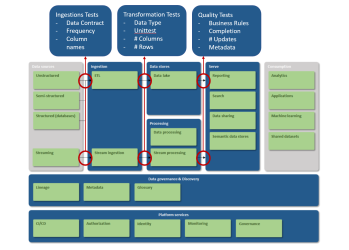
Een Data Pipeline is onder te verdelen in verschillende onderdelen. De data stromen van het ene blok naar het volgende blok. Bij elke transitie kunnen tests gedaan worden. Hieronder staat een referentiearchitectuur van een Modern Data Platform. Op het moment dat de data voor het eerst binnen komen, onderwerpen we deze direct aan een aantal testen. Dat noemen we de Ingestion Tests. Om verder gebruik te maken van de data, worden deze getransformeerd. In deze fase testen we met Transformation Tests. De laatste testfase is tijdens het schoonmaken van de data en noemen wel Quality Tests. We leggen deze begrippen verder uit.
Ingestion Tests
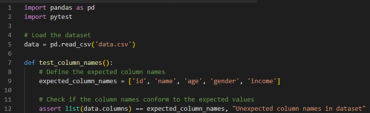
Op het moment dat je voor de eerste keer met de data in contact komt, kunnen er direct testen worden geschreven. Deze testen controleren of er geen aanpassingen zijn bij de bron, die veel later in het proces tot problemen leiden. Kom je er pas aan het einde van het proces achter dat er iets mis is, ben je veel tijd kwijt met het vinden van het probleem. Dat willen we voor zijn met de Ingestion Tests. Eenvoudige tests om vooral het datacontract te controleren. Is er geen datacontract aanwezig, dan is het advies om deze af te spreken met de leverancier van de data. Tests om het naleven van het datacontract te controleren bestaan veelal uit controles van de eigenschappen van de data:
- Klopt de frequentie van de aanlevering
- Klopt het aantal kolommen, zie voor voorbeeldcode de snippet hieronder
- Zijn de namen van de kolommen zoals verwacht
- Is de grootte van het bestand binnen een bepaalde range
- Heeft de data de gewenste structuur
Je kan ook al wat verder kijken dan het datacontract, denk dan bijvoorbeeld aan:
- Wat verwacht je van de statistische distributie van de aanlevering. Verschuivingen in de statistische distributie kunnen aangeven dat de brondata aan het schuiven zijn, wat weer invloed op het model kan hebben. Wat en of er impact is door verandering van de statistische distributie is sterk situatie afhankelijk.
- Zitten er persoonlijke of privacygevoelige gegevens in de aanlevering, die er al dan niet thuishoren. Bijvoorbeeld een BSN nummer waar geen goede rede voor is.
Transformation Tests
De data zijn binnengekomen, en we gaan deze bewerken om waarde te creëren. Daar komen transformaties bij kijken en transformaties kunnen fouten introduceren, daar maken we dus testen voor. Denk hierbij aan de volgende zaken die gevalideerd kunnen worden:
- Komt het data type overeen met de verwachting
- Unit testen voor reguliere ontwikkeling
- Komt het aantal kolommen overeen met wat wordt verwacht na de transformatie
- Komen het aantal rijen overeen met wat wordt verwacht na de transformatie
![]()
Quality Tests
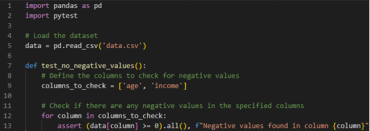
Richting het einde van de Data Pipeline kijken we nog wat dieper naar de inhoud van de data om de kwaliteit te controleren. Betrek hier ook de Business bij, die hebben de domeinkennis die nodig is om zinnige testen te schrijven voor datakwaliteit. Zorg dat de Business een integraal onderdeel wordt van het hoog houden van de datakwaliteit door collega’s actief te betrekken. Stel vragen over de data, waarom komen we in kolom ‘income’ alleen maar positieve bedragen tegen, is dat altijd zo? Uit zulke vragen komt bijvoorbeeld naar voren dat ‘income’ altijd een positief bedrag moet zijn, dat verwerk je dan in een test zoals in het voorbeeld hieronder. De domeinkennis van collega’s uit de business kant is essentieel om effectief de kwaliteit van de data te kunnen testen, zoek dus actief de business op bij het maken van deze testen. In een ideale wereld ontstaat er een samenspel tussen de techniek en business waarbij deze elkaar actief vinden om de datakwaliteit te verbeteren. Zoek met het maken van testen in deze fase naar antwoorden op de volgende vragen:
- Voldoet data aan vooraf gestelde business rules
- Is de data compleet, of zijn velden leeg
- Is er sprake van data drift, een verschuiving in de statistische distributie van de data die invloed kan hebben op een model getraind op deze data
Hoe te starten?
Start met het bouwen van testen. Doe een risicoanalyse om te identificeren waar je de meeste impact kan maken. Begin klein met het schrijven van testen. Hou bij elke test die je schrijft rekening met of deze in de Innovation of de Value Pipeline valt. In dit artikel staan een aantal eenvoudige testen beschreven die in elk project toepasbaar zijn, zoals de harde checks tijdens de Ingestion op het aantal kolommen of rijen. Ondanks de simpliciteit kunnen deze al heel veel impact maken. De volgende stap is uitbouwen van nieuwe testen en onderhouden van bestaande testen. Laat zien aan je organisatie wat de impact is van de informatie die je krijgt uit de testen. Deze feedback activeert ook de business om mee te denken en zo een integraal onderdeel te worden van het testproces. Niet alleen dat, de business krijgt zo ook meer inzicht in de impact van de data die zij creëren. Door dit geheel samen te brengen worden je testen continu verbeterd en uitgebreid, zo behaal je de maximale impact van DataOps.